

黄立峰
我的经历
以下是我成长的足迹

华南农业大学
2022 - 今
数学与信息学院 计算机科学与工程系

中山大学
2012-2015 | 2018 - 2022
硕士 计算机应用技术 | 博士 网络空间安全

西南交通大学
2008-2012
学士 网络工程
我的课程
操作系统、Linux系统及程序设计、算法分析与设计

《操作系统》

《Linux系统及程序设计》

《算法分析与设计》
我在做什么
人工智能、深度学习、对抗学习攻防
对抗攻防学习综艺节目:《燃烧吧!天才程序员》
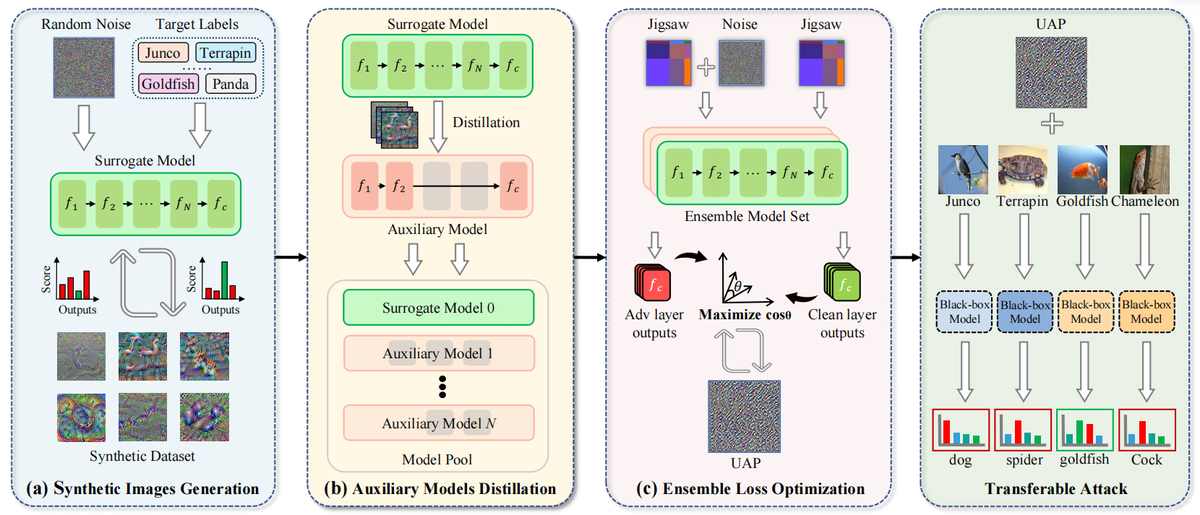
Improving Transferability of Data-Free Universal Adversarial Perturbations via Auxiliary Ensembles
Lifeng Huang, Han Wang, Chen Wan, Zusheng Zhang, Shaojian Qiu*, Qiong Huang
简介: 不同于大多数针对单个样本定制扰动的对抗攻击,通用对抗扰动(UAP) 旨在让模型在各类数据上均出现判断失误。这一特性使得通用对抗扰动十分适用于在真实场景下评估深度模型的鲁棒性。在实际攻击场景中,攻击者往往无法获取目标数据,而无数据方法可在不使用目标模型训练数据的前提下生成通用对抗扰动。但我们发现,现有无数据通用对抗扰动攻击普遍存在严重过拟合问题,导致扰动迁移性较差,难以应用于黑盒模型评估。针对该问题,本文提出一种全新的无数据通用对抗扰动攻击方法 ——面向可迁移通用对抗扰动的辅助集成方法(AE-UAP)。具体而言,我们对现有替代模型的前向传播路径进行剪枝,构建出多个辅助模型,并利用人工合成数据集对辅助模型开展微调。随后,联合替代模型与辅助模型执行多层集成优化:通过最大化各模型中间层中对抗样本与干净样本的特征差异,完成扰动迭代。为引导通用对抗扰动学习泛化能力更强的底层特征,我们对替代模型与辅助模型的攻击流程进行层级剪枝,将优化重心聚焦于网络浅准。
IEEE MultiMedia (TMM, 2026) (CCF-A)
[论文] [代码]
AUTE: Peer-Alignment and Self-Unlearning Boost Adversarial Robustness for Training Ensemble Models
Lifeng Huang, Tian Su, Chengying Gao, Ning Liu, Qiong Huang*
简介: 抗攻击对基于人工智能的系统安全构成了重大威胁。为了应对这些攻击,对抗训练(Adversarial Training, AT)和集成学习(Ensemble Learning, EL)已经成为提升模型鲁棒性的广泛采用的方法。然而,一个反直觉的现象是,这两种方法的简单组合可能会降低集成模型的对抗鲁棒性。在本文中,我们提出了一种名为 AUTE的新方法,旨在有效结合AT和EL,最大化两者的优势。具体来说,AUTE包含两个关键组成部分:首先,AUTE以循环的方式将集成模型划分为一个“大模型”和单个成员模型,并对它们的输出进行对齐,从而提升每个成员的鲁棒性。其次,AUTE引入了“遗忘”的概念,主动忘记具有过度自信特性的特定数据,以保留模型学习更鲁棒特征的能力。在多个数据集和网络结构上的广泛实验表明,AUTE相较于基线方法表现更为优越。例如,基于ResNet-20网络的5成员AUTE在分类干净数据和对抗数据上分别比最先进的方法提高了2.1%和3.2%。此外,AUTE可以轻松扩展到非对抗训练范式,在当前的标准集成学习方法中表现出显著优势。
AAAI Conference on Artificial Intelligence (AAAI, 2025) (CCF-A)
[论文] [代码]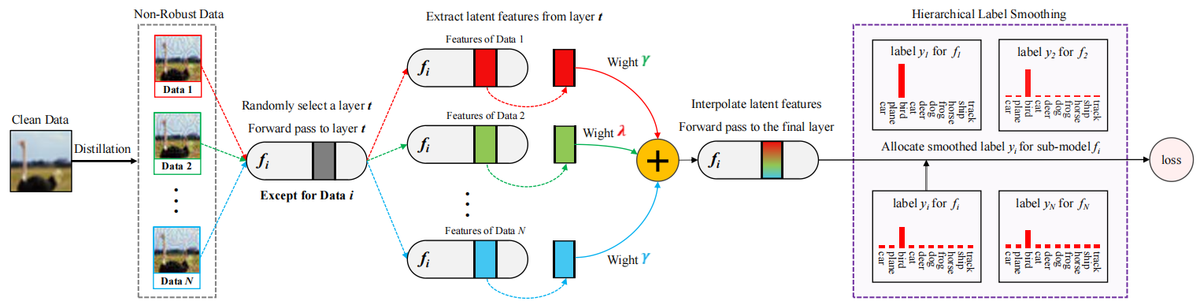
LAFED: Towards Robust Ensemble Models Via Latent Feature Diversification
Wenzi Zhuang†, Lifeng Huang†, Chengying Gao, Ning Liu*
简介: 对抗样本对深度神经网络(DNNs)的安全性构成重大挑战。 为了抵御恶意攻击,对抗性训练迫使DNNs抑制泛化但非鲁棒的特征来学习另一些更为鲁棒的特征,从而提高了安全性,但导致了准确性下降。 另一方面,集成训练通过训练多个子模型来预测数据,以提高鲁棒性,并在干净数据上仍然实现了令人满意的准确性。 尽管如此,先前的集成方法由于未能增加模型多样性,仍然容易受到对抗攻击。 我们从数据的角度重新审视模型多样性,发现训练批次之间的高相似性会减少特征多样性,因此削弱了集成模型的鲁棒性。 为此,我们提出了LAFED,在优化过程中重建具有多样特征的训练集,增强了集成模型的整体鲁棒性。 对于每个子模型,LAFED将从其他子模型中提取的脆弱性视为原始数据,然后以潜在空间中的随机方式与轮次更改的权重相结合。 这导致了新特征的形成,并显著降低了子模型之间学习表示的相似性。 此外,LAFED通过利用层次平滑标签增强了集成模型内的特征多样性。 大量实验证明,与当前方法相比,LAFED显著增强了对抗鲁棒性。Pattern Recognition (PR), 2024 (中科院 1区/CCF-B)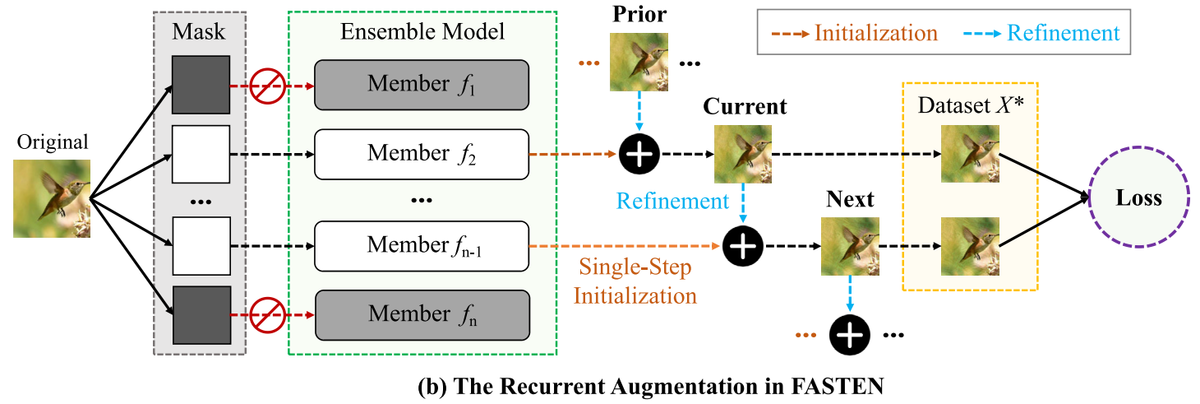
FASTEN: Fast Ensemble Learning For Improved Adversarial Robustness
Lifeng Huang, Qiong Huang, Peichao Qiu, Shuxin Wei, Chengying Gao*
简介: 最近的研究表明对抗攻击威胁深度神经网络(DNNs)的安全性。 为了解决这个问题,学术界已经提出了集成学习方法,通过训练多个子模型提高对抗性。 然而,这些方法通常伴随着高计算成本,包括多步优化以生成高质量的增强数据和额外的网络传递以优化复杂的正则项。 在本文中,我们提出了FAST ENsemble学习方法(FASTEN),以显著降低数据生成和正则优化方面的成本。 首先,FASTEN采用单步技术初始化较弱的增强数据,并回收历史知识以增强数据质量,从而大幅减少数据生成预算。 其次,FASTEN引入了一种低成本的正则化器,以增加模型内相似性和模型间多样性,其中大多数组件在无需网络传播的情况下完成计算,进一步降低了算力成本。 通过在各种数据集和网络上的实证结果表明,FASTEN在较少资源需求的同时实现了更高的鲁棒性。 例如,与最先进的DVERGE和TRS相比,5个成员的FASTEN将优化过程加速了7倍和28倍。 此外,FASTEN在黑盒和白盒攻击下分别以26.3%和6.1%的优势超过SOTA方法。 FASTEN还与现有的快速对抗训练技术兼容,使其成为提高鲁棒性而不产生过多计算成本的有利选择。
IEEE Transactions on Information Forensics and Security (TIFS), 2023 (中科院 1区/CCF-A)
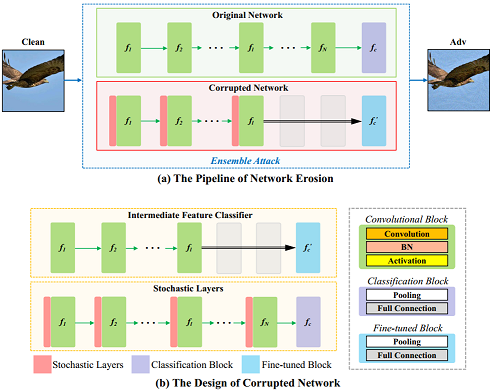
Erosion Attack: Harnessing Corruption To Improve Adversarial Examples
Lifeng Huang, Chengying Gao*, Ning Liu
简介: 尽管对抗样本对深度神经网络构成了严重的威胁,但大多数可迁移对抗攻击对黑盒防御模型并不起作用。 这可能导致人们错误地认为对抗样本并不真正具有威胁性。 在本文中,我们提出了一种新颖的可迁移对抗攻击,可以击败各种黑盒防御模型,并展现了它们的安全局限性。 我们确定了当前攻击方法可能失败的两个内在原因,即数据依赖性和网络过拟合。它们为提高攻击迁移性提供了不同的视角。 为了减轻数据依赖性效应,我们提出了数据侵蚀方法。 它涉及到找到特殊的增强数据,在普通模型和防御中表现出相似的特性,以帮助攻击者欺骗更具鲁棒性的模型。 此外,我们引入了网络侵蚀方法来克服网络过拟合困境。这个想法在概念上很简单: 它将单个代理模型扩展到高多样性的集成结构,从而产生迁移性更强的对抗性样本。 提出的两个方法可以整合起来进一步增强可迁移性,称为侵蚀攻击(EA)。 我们评估了提出的EA在不同的防御下的攻击能力,实证结果证明EA优于现有的可迁移攻击,并揭示了当前强化模型面临的潜在威胁。
IEEE Transactions on Image Processing (TIP), 2023 (中科院 1区/CCF-A)
[论文] [代码]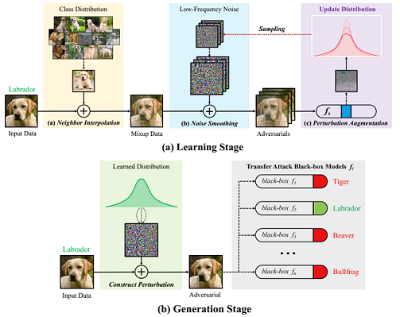
DEFEAT: Decoupled Feature Attack Across Deep Neural Networks
Lifeng Huang, Chengying Gao, Ning Liu
简介: 对抗性攻击对深度神经网络构成了安全挑战,促使研究人员建立各种防御方法。 因此,黑盒攻击在防御场景下性能下降。一个重要的观察结果是,一些特征级攻击在欺骗没有防御机制的模型的场景中成功率很高, 而在遇到防御机制时它们的可迁移性会严重下降,这会给人一种虚假的安全感。 在本文中,我们解释造成这种现象的一个可能原因是域过拟合效应,它会降低特征扰动图像的跨域迁移能力, 使它们很难欺骗对抗性训练防御。为此,我们研究了一种新颖的特征级方法,称为解耦特征攻击(DEFEAT)。 与当前分别估计梯度估计并更新扰动的循环模式攻击方法不同,DEFEAT 将对抗样本生成过程和扰动对抗优化过程二者进行解耦。 在第一阶段,DEFEAT 学习一个充满了具有高对抗效应的扰动的分布。 然后在第二阶段,它迭代地从学习到的分布中随机采样,组成迁移对抗样本。 最重要的是,我们可以将现有的增强变换技术应用到 DEFEAT 框架中,以产生更强大的对抗扰动。 我们还提供了对可迁移性和模型潜在特征之间关系的分析,这有助于社区了解对抗性攻击的内在机制。 在多种黑盒防御模型上评估的大量实验表明了 DEFEAT 有效缓解域过拟合,比现有方法拥有更强的性能。
Neural Networks, 2022 (中科院 1区/CCF-B)
[论文] [代码]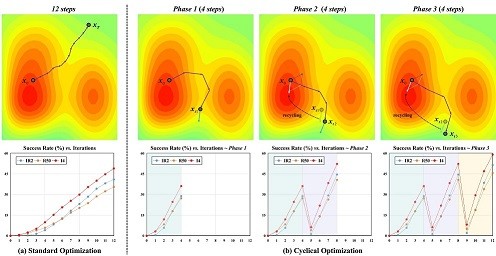
Cyclical Adversarial Attack Pierces Black-box Deep Neural Networks
Lifeng Huang, Shuxin Wei, Chengying Gao, Ning Liu*
简介: 深度神经网络 (DNN) 已显示出抵抗对抗性攻击的脆弱性。通过利用对抗样本的可迁移性, 攻击者可以在不访问底层黑盒模型信息的情况下欺骗人工智能系统。然而,大部分对抗样本迁移到防御模型时往往表现不佳, 这可能会给人一种虚假的安全感。在本文中,我们提出了循环对抗攻击(CA2),这是一种通用且直接的方法, 可提高可转移性以攻破防御模型。我们首先从优化的角度重新审视基于动量的方法,发现它们通常存在可迁移性饱和困境。 为了解决这个问题,CA2执行循环优化算法来生成对抗样本。与累积速度以不断更新解决方案的标准动量策略不同, 我们将生成过程分为多个阶段,并将前一阶段的速度向量视为适当的知识,以指导更大步长的新对抗性攻击。 此外,CA2在每次优化时以循环方式应用一种新颖且兼容的增强算法,以进一步增强黑盒可迁移性,称为循环增强。 在各种模型上进行的大量实验不仅验证了每个设计算法在 CA2中的有效性,而且还说明了我们的方法与现有迁移对抗攻击相比的优越性。
Pattern Recognition (PR), 2022 (中科院 1区/CCF-B)
[论文] [代码]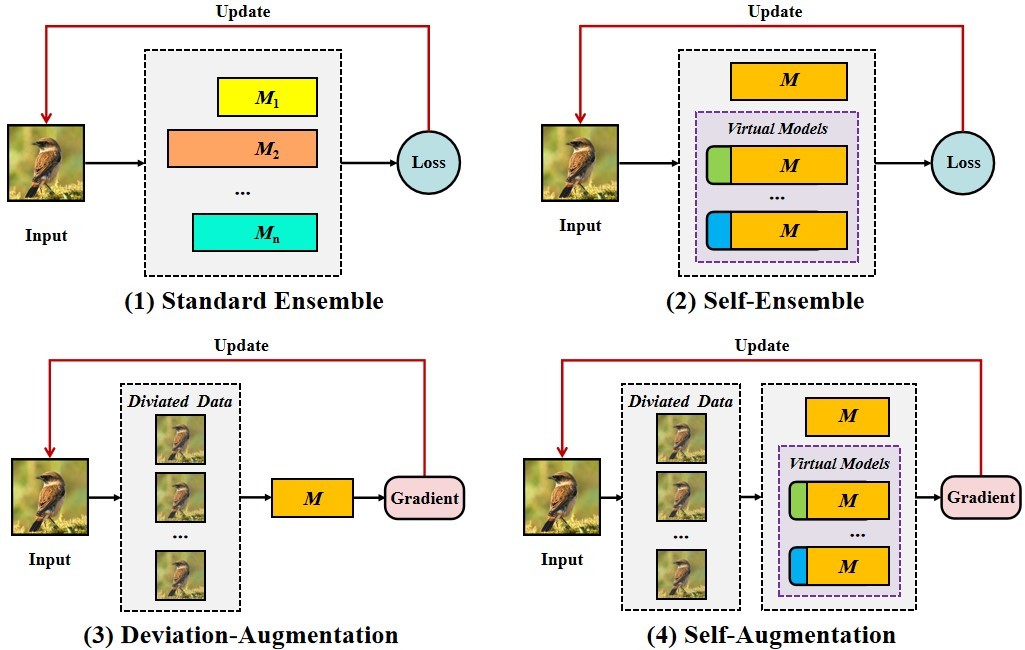
Enhancing Adversarial Examples Via Self-Augmentation
Lifeng Huang, Wenzi Zhuang, Chengying Gao, Ning Liu*
简介: 最近,对抗性攻击对深度神经网络的安全性提出了挑战,这促使研究人员建立各种防御方法。 然而,目前的防御措施是否足以实现真正的安全? 为了回答这个问题,我们提出了一种自我增强方法(SA)来规避防御者到可迁移的对抗样本。 具体而言,自增强包括两种策略: (1)自身集成,将额外的卷积层应用于现有深度神经网络以构建各种虚拟模型, 再将这些虚拟模型的输出层融合在一起以实现集成模型效果并防止过度拟合; (2)偏差增强,它基于对防御模型的观察,即输入数据被高度弯曲的损失面包围, 从而启发我们将偏差向量添加于输入数据,使其逃离局部的空间。 值得注意的是,我们可以自然地将自我增强与现有的迁移攻击方法相结合, 以建立更多更强的可迁移的对抗性攻击。 我们对四种普通模型和十种防御方法进行了大量实验, 结果表明与最先进的可迁移攻击相比我们的方法具有较大优越性。
International Conference on Multimedia & Expo (ICME, 2021) (*oral) (CCF-B)
[论文] [代码]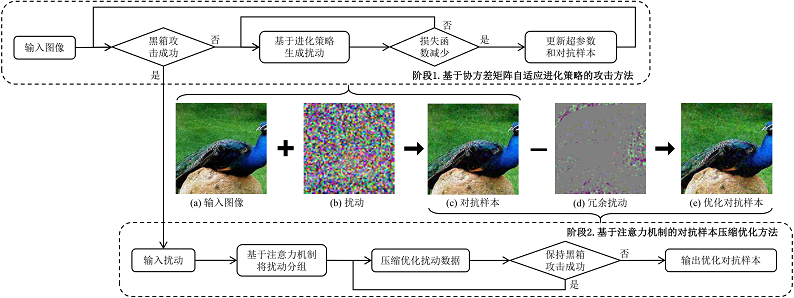
一种基于进化策略和注意力机制的黑盒对抗攻击算法
黄立峰,庄文梓,廖泳贤,刘宁*
简介: 深度神经网络在许多计算机视觉任务中都取得了优异的结果,并在不同领域中得到广泛应用。 然而研究发现,在面对对抗样本攻击时,深度神经网络表现得较为脆弱,严重威胁着各类系统的安全性。 在现有的对抗样本攻击中,由于黑盒攻击具有模型不可知性质和查询限制等约束,更接近实际的攻击场景, 但现有的黑盒攻击方法存在攻击效率较低与隐蔽性弱的缺陷。因此,本文提出了一种基于进化策略的黑盒对抗攻击方法, 充分考虑了攻击过程中梯度更新方向的分布关系,自适应学习较优的搜索路径,提升攻击的效率。 在成功攻击的基础上,结合注意力机制,基于类间激活热力图将扰动向量分组和压缩优化, 减少在黑盒攻击过程中积累的冗余扰动,增强优化后的对抗样本的不可感知性。 通过与其他四种最新的黑盒对抗攻击方法(AutoZOOM,QL-Attack,FD-Attak,D-based Attack) 在七种深度神经网络上进行对比,验证了本文提出方法的有效性与鲁棒性。
软件学报, 2021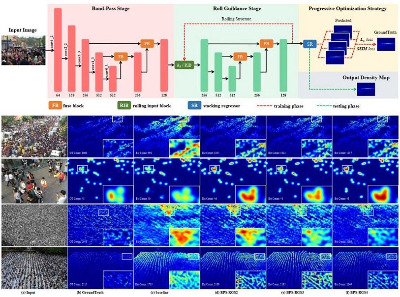
Scale-aware Progressive Optimization Network
Ying Chen, Lifeng Huang, Chengying Gao, Ning Liu
简介: 人群计数由于广阔的应用前景而引起了越来越多地关注。 该领域最大的挑战之一是人群尺度的巨大变化,其严重影响了密度估计的准确性。 为此,本文提出了一种用于人群计数的尺度感知渐进优化网络(SPO-Net), 该网络可以克服高度拥挤场景中的尺度变化问题以实现高质量的密度图估计。 具体而言,SPO-Net的第一阶段(BPS)主要集中于对输入图像进行预处理, 并从分离的多层特征中融合高级语义信息和低级空间信息。 SPO-Net的第二阶段(RGS),旨在从多尺度特征和循环训练方式中学习一个尺度适应的网络。 此外,为了更好地学习多尺寸区域的局部相关性并减少冗余计算,网络在每次循环中引入了具有类比目标的不同监督, 称为渐进优化策略。 本文在三个具有挑战性的人群计数数据集上进行的广泛实验不仅证明了SPO-Net中每个部分的有效性, 而且证明了本文提出的方法与以往方法相比的优越性。
ACM MultiMedia (ACM MM, 2020) (CCF-A)
[论文]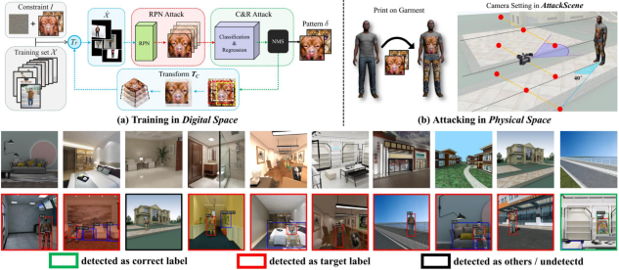
Universal Physical Camouflage Attacks on Object Detectors
Lifeng Huang, Chengying Gao, Yuyin Zhou, Changqing Zou, Cihang Xie, Alan Yuille, Ning Liu
简介: 论文提出了一种物理场景下对抗攻击检测模型的方法。现有的方法通常只能生成个体级别的伪装图案, 且约束物体需具备刚体或平面的特征(如路牌、车等),难以在实际中应用。针对这些缺陷, 该工作提出了一种通用级别的伪装攻击框架,可以对一类中所有实例物体进行有效的攻击, 且在非刚体与非平面的攻击场景下保持了较高的鲁棒性。该方法的主要思路包括两部分:
(1)数据生成阶段,即通过同时对复杂对象的内在性质(如形变、遮挡等)与外在环境(如光照、角度等) 进行物理仿真,生成拟真数据集;(2)联合攻击阶段,即基于生成的数据集对RPN网络和分类网络同时展开攻击, 结合语义约束降低攻击目标的置信度。两个阶段以迭代优化的方式生成伪装图案。 此外,针对该领域缺少评估环境的困境,该工作构建了一个参数可控的合成数据库(AttackScenes)。 通过大量的实验证明,该工作提出的方法不仅能在虚拟场景和现实世界中对目标检测模型进行有效的攻击, 还展现出较好的泛化性与迁移性。
Computer Vision and Pattern Recognition (CVPR, 2020) (CCF-A)
[论文] [项目主页]
















